Задача на сегодня 1368. Minimum Cost to Make at Least One Valid Path in a Grid - достаточно стандартная вариация лабиринта с бесплатными переходами.
📝 Описание задачи
У нас есть поле размером m×n, где каждая клетка содержит указание направления движения. Необходимо найти минимальную стоимость перехода из левого верхнего угла (0, 0) в правый нижний угол (m−1,n−1).
Каждая клетка указывает направление движения:
1 — вправо,2 — влево,3 — вниз,4 — вверх.
Изменение направления перехода возможно, но со стоимостью 1, и его можно выполнить только один раз для каждой клетки.
💡 Идея
Поле можно рассматривать как ориентированный граф, где клетки являются вершинами, а направления задают ребра. Наша цель — найти минимальную стоимость пути из начальной клетки в конечную. Для этого используется модифицированный BFS с двумя очередями, где приоритет отдается движениям без изменения направления.
🛠️ Детали подхода
- Две очереди:
Читать дальше →
ответить
Ссылка на задачу — 889. Construct Binary Tree from Preorder and Postorder Traversal.
📌 Описание задачи
Нам даны прямой (preorder) и обратный (postorder) обходы бинарного дерева.
Необходимо восстановить дерево по этим обходам.
Основные свойства обходов:
- Preorder (прямой обход):
[корень → левый → правый]
- Postorder (обратный обход):
[левый → правый → корень]
💡 Идея
Для построения дерева используем рекурсивный подход, основанный на двух ключевых наблюдениях:
- 1️⃣ Каждый новый узел получает значение из
preorder
→ так мы всегда сначала создаем корень поддерева.
- 2️⃣ Поддерево считается полностью построенным, когда его значение встречается в
postorder
→ это сигнал к завершению рекурсии.
🔍 Детали подхода
- Используем итераторы
Peekable<Iterator> для эффективного прохода по preorder и postorder.
- Берем значение из
preorder и создаем новый узел.
- Рекурсивно создаем левое поддерево, если
postorder пока не указывает на текущий корень.
Читать дальше →
ответить
Ссылка на задачу - 1780. Check if Number is a Sum of Powers of Three.
📌 Описание задачи
Дано число n. Нужно определить, можно ли представить его в виде суммы различных степеней тройки.
🔹 Пример:
- 📥 Ввод:
n = 12
- 📤 Вывод:
true
- 💡 Объяснение:
12 = 3⁰+3¹+3² = 1 + 3 + 9.
💡 Идея
Рассмотрим представление n в троичной системе счисления:
- Если в записи числа есть цифра
2, то решения нет (так как нельзя взять две одинаковые степени).
- Если в записи есть только
0 и 1, то решение существует (мы просто берём соответствующие степени тройки).
Таким образом, задача сводится к поразрядной проверке числа в троичной системе счисления.
🚀 Детали подхода
Будем использовать рекурсию и деление числа на 3:
- База рекурсии: Если
n == 0, то мы успешно разложили число, возвращаем true.
- Шаг рекурсии: Если
n % 3 == 2, то n нельзя разложить, возвращаем false.
- Рекурсивный вызов: Проверяем
n / 3, повторяя процесс.
⏱ Асимптотика
- Временная сложность:
O(log n), так как n уменьшается в 3 раза за итерацию.
- Пространственная сложность:
O(log n) из-за глубины рекурсии
(несложно алгоритм преобразовать в цикл, чтобы получить O(1)).
📝 Исходный код
impl Solution {
pub fn check_powers_of_three(n: i32) -> bool {
n == 0 || (n % 3 != 2 && Self::check_powers_of_three(n / 3))
}
}
Tags: #rust #algorithms #math
ответить
Задача третьего дня Advent of Code — Mull It Over.
📘 Часть I. Описание задачи
- В дампе памяти содержатся команды вида
mul(X,Y), где X и Y — это числа от 1 до 999.
- Такие команды представляют собой простое умножение двух чисел.
- Однако память повреждена, и в тексте могут встречаться невалидные команды
(например: "mul(4*," "mul ( 2 , 3 )" и т.п.).
Необходимо выделить все корректные mul(X,Y) и подсчитать сумму произведений.
💡 Идея
Парсим только строки, точно соответствующие регулярному выражению "mul(\d{1,3},\d{1,3})", остальные пропускаем. После чего результат каждого умножения суммируем.
📘 Часть II. Описание задачи
Кроме mul, в дампе встречаются do() и don't():
do() включает обработку muldon't() отключает
По умолчанию mul разрешён. Надо подсчитать только те mul, которые активны в момент встречи.
💡 Идея
Читать дальше →
ответить
Сегодня у нас интересная задача на битовые манипуляции – 2429. Minimize XOR.
📜 Описание задачи
Дано два положительных числа num1 и num2. Нужно найти число x, такое что:
- Количество установленных битов в числе
x равно количеству установленных битов в num2.
- Результат операции
XOR между x и num1 минимален.
💡 Идея
Для минимизации XOR мы
- Стремимся сохранить как можно больше старших битов из числа num1, так как они оказывают наибольшее влияние на минимизацию результата.
- Если остаются неиспользованные биты, мы добавляем младшие биты, чтобы завершить формирование числа x с требуемым количеством установленных битов.
✨ Детали подхода
-
Подсчёт установленных битов:
- Используем метод
count_ones, чтобы подсчитать количество установленных битов в числе num2.
-
Сохранение старших битов:
- Проходим по битам
num1 с самого старшего до младшего.
- Если бит установлен, включаем его в результат и уменьшаем счётчик оставшихся битов.
Читать дальше →
1 ответ
Ссылка на задачу – 1726. Tuple with Same Product.
📜 Описание задачи
Дан массив nums из различных положительных чисел. Нужно вернуть количество кортежей (a, b, c, d), таких что произведение a * b равно произведению c * d, при условии, что все элементы кортежа различны.
💡 Идея
- Для каждой уникальной пары элементов из массива nums вычисляем произведение и подсчитываем частоту его появления с помощью HashMap.
- Для каждого произведения, встречающегося больше одного раза необходимо учесть, что существует 8 уникальных вариантов составления кортежей:
a*b=c*d; a*b=d*c; b*a=c*d; b*a=d*c; c*d=a*b; c*d=b*a; d*c=a*b; d*c=b*a
- Соответственно, итоговый вклад, каждого произведения вычисляется как
4 * frequency * (frequency - 1)
🔍 Детали подхода
- Подсчет в HashMap:
- Используем два вложенных цикла для перебора всех уникальных пар
(i, j) с условием i < j и вычисляем их произведение.
- Результаты произведений сохраняем в
HashMap, где ключ — это само произведение, а значение — количество его вхождений.
- Расчет кортежей:
- Для каждого произведения с частотой больше
1, добавляем в итоговый результат значение
4 * frequency * (frequency - 1).
- Возврат результата:
Читать дальше →
1 ответ
Первая задача в этом году - 1422. Maximum Score After Splitting a String несложная, и интересно решить её за один проход по массиву.
📋 Описание задачи
Дана бинарная строка, состоящая из символов 0 и 1.
Требуется найти максимальный результат разбиения строки на две непустые подстроки.
Результат определяется как:
Результат = (Количество нулей в левой подстроке) + (Количество единиц в правой подстроке).
💡 Идея
Для эффективного решения задачи:
- Рассчитаем динамический баланс для каждого допустимого разбиения строки. Баланс показывает, насколько выгодно разделить строку в конкретной точке.
- Пройдем по строке, обновляя текущий баланс и максимальный результат. Пропустим последнюю итерацию, чтобы обе подстроки оставались непустыми.
🔍 Подробности подхода
- Формула результата: Для разбиения в точке
i:
Result = zero_count + (total_ones - ones_count)
, где:
zero_count – число нулей слева
Читать дальше →
ответить
Сегодня нас опять радует задачка на методы динамического программирования - 2466. Count Ways To Build Good Strings.
😊 Описание задачи
Нам нужно подсчитать количество "хороших строк", длина которых находится в диапазоне [low, high].
Хорошая строка создаётся из пустой строки путём выполнения следующих операций:
- Добавление символа
'0' ровно zero раз.
- Добавление символа
'1' ровно one раз.
Результат может быть очень большим, поэтому необходимо вернуть его по модулю 10⁹+7.
💡 Идея
Для решения задачи мы используем динамическое программирование.
Каждое состояние dp[length] хранит количество способов построить строку длины length.
Постепенно вычисляя значения для всех длин от 1 до high, мы получаем итоговый результат.
🔍 Подробности подхода
- Инициализация:
- Создаём массив
dp длиной high+1, где dp[length] будет содержать количество способов построить строку длины length.
- Базовый случай:
dp[0] = 1, так как существует ровно один способ создать пустую строку.
Читать дальше →
ответить
Сегодня рассмотрим достаточно простое решение задачи 2779. Maximum Beauty of an Array After Applying Operation.
Условие 📋
Дан массив nums и целое неотрицательное число k. Разрешается заменить каждый элемент массива (не более одного раза) любым числом из диапазона [nums[i]−k,nums[i]+k]. Требуется найти максимальную длину подпоследовательности массива, состоящей из одинаковых элементов (это называется "красота массива").
Идея 💡
Фактически задача сводится к нахождению наибольшего подмножества массива, все элементы которого укладываются в интервал длины 2×k. Чтобы эффективно найти такой диапазон, можно использовать метод скользящего окна по предварительно отсортированному массиву.
Подход 🛠️
- Сортировка массива: Упорядочиваем массив, чтобы элементы, которые могут принадлежать одному диапазону, оказались рядом.
- Скользящее окно: Используем два указателя (
l и r) для определения максимального диапазона, удовлетворяющего условию nums[r]−nums[l]≤2×k.
- Подсчёт длины диапазона: На каждом шаге обновляем результат как максимум текущей длины окна
r−l.
Асимптотика 📊
- Временная сложность:
O(nlogn) из-за сортировки + O(n) для скользящего окна, итого O(nlogn).
- Пространственная сложность:
O(1), если используется сортировка "на месте".
Исходный код решения
impl Solution {
pub fn maximum_beauty(nums: Vec<i32>, k: i32) -> i32 {
// Create a mutable copy of nums and sort it
let mut sorted_nums = nums.clone();
sorted_nums.sort_unstable();
let mut max_beauty = 0;
let mut right = 0;
// Iterate over each number in the sorted array
for left in 0..sorted_nums.len() {
// Expand the right pointer as long as the difference is within the allowed range
while right < sorted_nums.len() && sorted_nums[right] <= sorted_nums[left] + 2 * k {
right += 1;
}
// Update the maximum beauty based on the current window size
max_beauty = max_beauty.max((right - left) as i32);
}
max_beauty
}
}
На нашей новой задаче 2415. Reverse Odd Levels of Binary Tree есть повод продемонстировать продвинутые методы Rust работы с итераторами (std::iter::successors & std::iter::zip), а также "непристойную" работу c реф-каунт ячейками :(
📜 Описание задачи
Дано идеальное бинарное дерево. Требуется изменить порядок значений узлов на всех нечетных уровнях дерева.
Идеальное дерево — это дерево, где у каждого узла два потомка, а все листья находятся на одном уровне.
💡 Идея
Мы адаптируем BFS для обхода дерева по уровням. На каждом уровне проверяется, нужно ли инвертировать порядок значений (для нечетных уровней). С помощью вспомогательной функции формируются следующие уровни дерева.
📋 Подробности подхода
-
Вспомогательная функция
next_level:
- Формирует следующий уровень дерева, собирая всех левых и правых потомков текущих узлов.
-
Завершение обработки:
- Проверка, что текущий уровень является листовым, выполняется через условие
nodes[0].borrow().left.is_none().
- При достижении уровня листьев обработка завершается.
-
Обход уровней с помощью
std::iter::successors:
- Используется функциональный подход для последовательного формирования уровней дерева. Итератор автоматически останавливается при достижении листового уровня.
Читать дальше →
ответить
Очередная наша задача - 2593. Find Score of an Array After Marking All Elements. Ну и так как наша цель не просто решать, а показывать имплементацию разных техник, то воспользуемся-ка мы идеей битового множества (его в стандартную библиотеку Rust еще "не подвезли", так что и операции имплементируем сами).
Задача 🧩
Дан массив положительных целых чисел nums. Ваша цель — получить максимальное значение score, выполняя следующие действия:
- Выберите наименьший немаркированный элемент массива (при равенстве — элемент с меньшим индексом).
- Добавьте значение этого элемента к
score.
- Пометьте выбранный элемент и его двух соседей (если они существуют).
- Повторяйте, пока все элементы не будут помечены.
Необходимо вернуть итоговое значение score.
Идея 💡
В данной задаче нужно эффективно следовать указанным правилам. Чтобы сделать это:
- (а) Мы отсортируем индексы массива nums по значениям, чтобы обрабатывать элементы в правильном порядке, начиная с наименьших.
- (б) Используем битовое множество (
Vec<u128>) для компактного представления состояния "помечен" для элементов массива.
Подход 🚀
Читать дальше →
ответить
Ссылка на задачу – 1790. Check if One String Swap Can Make Strings Equal.
Описание задачи 😊
Даны две строки s1 и s2 равной длины. Необходимо определить, можно ли сделать строки равными, совершив не более одного обмена символов в одной из строк.
Обмен — это операция, когда выбираются два индекса в строке и символы на этих позициях меняются местами.
Идея 😊
Основная идея заключается в поиске позиций, на которых символы в строках различаются.
- Если различий нет, строки уже равны.
- Если различия ровно в двух позициях, то проверяем, поможет ли один обмен исправить ситуацию.
- В остальных случаях (1 или более 2 отличий) сделать строки равными одним обменом невозможно.
Детали подхода 🚀
-
Сбор различающихся индексов:
- Пройдемся по всем индексам строк и соберем в вектор те индексы, на которых символы в s1 и s2 различаются.
При этом достаточно собрать максимум 3 индекса.
-
Проверка случаев:
- Нет различий: Если вектор пуст, строки равны.
Читать дальше →
ответить
Ссылка на задачу с LeetCode — 2444. Count Subarrays With Fixed Bounds.
📋 Условие задачи
- Дан массив целых чисел
nums и два целых числа minK и maxK.
- Необходимо посчитать количество подотрезков (непрерывных подмассивов), в которых минимальный элемент равен
minK, а максимальный — maxK.
Пример:
- Ввод:
nums = [1,3,5,2,7,5], minK = 1, maxK = 5
- Вывод:
2
- Пояснение: Подходящие подотрезки — [1,3,5] и [1,3,5,2].
💡 Идея
- Элементы, выходящие за пределы
[minK, maxK], ломают возможность создать валидный подотрезок.
- Поэтому нужно работать только с кусками массива, где все элементы находятся внутри заданных границ.
- В каждом таком куске мы будем отслеживать последние появления
minK и maxK и считать количество возможных подотрезков на лету.
🛠️ Детали подхода
- Разбиваем массив на куски (
chunk_by), где элементы либо все в пределах [minK, maxK], либо все вне.
- Для каждого валидного куска (на каждой позиции):
- Запоминаем последние индексы появления
minK и maxK.
Читать дальше →
ответить
Ссылка на задачу – 3066. Minimum Operations to Exceed Threshold Value II.
📝 Описание задачи
Дан массив nums и число k. Мы можем выполнять следующую операцию, пока в массиве есть хотя бы два элемента:
- Взять два наименьших числа
x и y.
- Удалить их из массива.
- Добавить новое число
2·min(x,y) + max(x,y).
Необходимо найти количество операций, чтобы все числа в массиве стали ≥ k.
💡 Идея
Мы объединяем два наименьших числа, поэтому важно быстро находить и извлекать их.
Для этого можно использовать очередь с приоритетами (BinaryHeap), но в нашем случае можно действовать эффективнее.
🔹 Заведём две очереди (VecDeque):
orig_values — содержит исходные числа < k, отсортированные по возрастанию.new_values — хранит новые числа, появляющиеся в процессе операций, в гарантированно возрастающем порядке.
Благодаря двум упорядоченным очередям, минимальные элементы можно извлекать за O(1), а вся процедура будет работать эффективнее, чем с BinaryHeap.
Читать дальше →
ответить
Задача 7-го дня Advent of Code — Bridge Repair.
📘 Часть I. Условие задачи
У инженеров почти готова калибровка оборудования, но из формул пропали все операторы!
Остались только числа. В каждой строке входных данных указано:
- Слева — целевое значение;
- Справа — последовательность чисел.
Задача: вставить между числами операторы + и *, чтобы получить целевое значение.
Важно: выражения вычисляются строго слева направо, без учёта приоритетов операций.
Например:
190: 10 19
3267: 81 40 27
Требуется определить, какие строки могут быть истинными, и посчитать сумму их целевых значений.
💡 Идея
- Каждую строку можно представить как выражение, в которое надо вставить операторы.
- Количество вставок —
len(seq) - 1.
- Для каждой строки мы перебираем все возможные комбинации из операторов
+ и * и проверяем, приводит ли результат к целевому числу.
Так как порядок чисел менять нельзя и вычисления всегда происходят слева направо, задача хорошо ложится на рекурсивный перебор (бэктрекинг).
Читать дальше →
ответить
Сегодня на очереди задача 2825. Make String a Subsequence Using Cyclic Increments.
Описание задачи 📝
Даны две строки str1 и str2. Нужно определить, можно ли сделать str2 подпоследовательностью строки str1, выполнив не более одной операции циклического увеличения произвольного набора символов в str1.
Циклический сдвиг означает, что 'a' становится 'b', 'b' — 'c', ..., 'z' — 'a'.
Идея решения 💡
Задача почти идентична проверке подпоследовательности в строке. Единственное отличие — сравнение символов становится чуть сложнее из-за необходимости учитывать циклический сдвиг.
Мы выделяем проверку совпадения символов в отдельный метод, а в остальном используем стандартный алгоритм проверки подпоследовательности.
Реализация подхода 🚀
- Используем два итератора для последовательного прохода по символам строк.
- Для сравнения символов применяем отдельную функцию, учитывающую как прямое совпадение, так и циклический сдвиг.
- При совпадении текущего символа строки
str2 с символом из str1, переходим к следующему символу в str2.
- Если все символы
str2 найдены в str1 в правильном порядке, возвращаем true, иначе — false.
Сложность алгоритма 📊
Читать дальше →
ответить
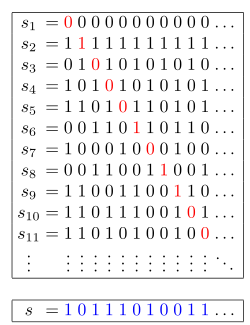
Ссылка на задачу — 1980. Find Unique Binary String.
Кайфовая задачка для тех, кто не прогуливал лекции по мат. анализу ☺
📌 Описание задачи
Дан массив nums, содержащий n различных бинарных строк длины n.
Необходимо найти любую бинарную строку длины n, которая не содержится в nums.
💡 Идея
Используем диагонализацию Кантора:
- Если пройти по диагонали массива строк и инвертировать каждый символ (
'0' → '1', '1' → '0'), то полученная строка гарантированно отличается от каждой строки в nums хотя бы в одном символе.
- Это означает, что такая строка не может присутствовать в
nums.
🔍 Подробности подхода
- Итерируемся по индексам
0..n.
- Берем
i-й символ i-й строки.
- Инвертируем его (
'0' → '1', '1' → '0').
- Собираем новые символы в строку и возвращаем её.
📊 Асимптотика
- Временная сложность:
O(n) — один проход по n элементам.
- Дополнительная память:
O(n) — единственное, что создаётся, это строка длины n.
Визуальный пример
🦀 Исходный код
impl Solution {
pub fn find_different_binary_string(nums: Vec<String>) -> String {
let n = nums.len();
// Generate a new binary string by flipping the diagonal elements.
(0..n)
.map(|i| Self::inverse_char(nums[i].as_bytes()[i] as char))
.collect()
}
fn inverse_char(c: char) -> char {
match c {
'0' => '1',
'1' => '0',
_ => unreachable!("Unexpected character: {}", c),
}
}
}
Tags: #rust #algorithms #math
ответить
Наша новая задача – 2425. Bitwise XOR of All Pairings решается "размышлениями на салфетке" и потом очень быстро и просто программируется.
📋 Описание задачи
Даны два массива nums1 и nums2, содержащие неотрицательные числа. Для каждой пары чисел, взятых из этих массивов, вычисляется побитовый XOR. Нужно вернуть результат XOR всех таких пар.
🧠 Идея
XOR обладает полезными свойствами:
- Результат XOR числа с самим собой равен
0 (a ^ a = 0).
- XOR ассоциативен и коммутативен, что позволяет упрощать вычисления.
Только если длина одного массива нечётная, элементы второго массива оказывают влияние на результат, так как они "непарные".
В итоге вклад в результат зависит от длины второго массива для каждого массива из входной пары.
😃 Детали подхода
- Найти длины массивов
nums1 и nums2.
- Если длина
nums2 нечётная, XOR всех элементов nums1 добавляется в результат.
- Если длина
nums1 нечётная, XOR всех элементов nums2 добавляется в результат.
- Возвратить результат как итоговый XOR.
⏱️ Асимптотика
-
Время:
O(n + m), где n и m — длины массивов nums1 и nums2.- XOR всех элементов каждого массива занимает линейное время.
-
Память:
O(1), используется небольшое число дополнительных переменных.
💻 Исходный код
use std::ops::BitXor;
impl Solution {
pub fn xor_all_nums(nums1: Vec<i32>, nums2: Vec<i32>) -> i32 {
let len_nums1 = nums1.len();
let len_nums2 = nums2.len();
// Initialize result as 0
let mut result = 0;
// If nums1 has an odd number of elements, XOR all elements of nums2
if len_nums1 % 2 == 1 {
result ^= nums2.into_iter().fold(0, i32::bitxor);
}
// If nums2 has an odd number of elements, XOR all elements of nums1
if len_nums2 % 2 == 1 {
result ^= nums1.into_iter().fold(0, i32::bitxor);
}
result
}
}
Задача на сегодня 2657. Find the Prefix Common Array of Two Arrays решается в лоб, но иногда стоит рассматривать и такие простые!
📝 Описание задачи
Даны две перестановки целых чисел A и B длины n. Необходимо вычислить массив общего префикса C, где C[i] равен количеству чисел, присутствующих в обеих перестановках на индексах от 0 до i.
Пример:
- Input:
A = [1,3,2,4], B = [3,1,2,4]
- Output:
[0,2,3,4]
💡 Идея
Чтобы быстро подсчитать количество общих элементов в префиксе, мы будем использовать два булевых массива для отслеживания того, какие элементы уже встречались в каждой из перестановок. Это позволит эффективно определять, какие элементы являются общими на каждом шаге.
📋 Подробности подхода
- Создаем два булевых массива
seen_in_a и seen_in_b длины n + 1 для отслеживания элементов, уже встреченных в A и B.
- Проходим по массивам
A и B одновременно:
- Помечаем текущие элементы
A[i] и B[i] как "увиденные".
- Увеличиваем счетчик общих элементов, если текущий элемент уже был встречен в другом массиве.
- На каждом шаге добавляем текущее значение счетчика общих элементов в результат.
Читать дальше →
ответить
Последняя в уходящем году задача 983. Minimum Cost For Tickets требует от нас несложного сочетания техник динамического программирования и скользящего окна.
📜 Условие задачи
У вас есть запланированные дни поездок в течение года, указанные в массиве days. Билеты можно приобрести по следующим ценам:
- Однодневный билет за
costs[0] долларов.
- Семидневный билет (покрывает любые последовательно идущие 7 дней) за
costs[1] долларов.
- Тридцатидневный билет (покрывает любые последовательно идущие 30 дней) за
costs[2] долларов.
Необходимо определить минимальные затраты, чтобы покрыть все дни из списка days.
💡 Идея
Для минимизации затрат можно использовать динамическое программирование.
Основная идея — поочередно вычислять минимальную стоимость для каждой даты из массива days, учитывая разные виды билетов, а также использовать индексы скользящих окон для эффективного вычисления диапазонов покрытия билетов.
🛠️ Детали подхода
- Создаем массив
dp, где dp[i] хранит минимальную стоимость поездок для первых i дней.
Читать дальше →
ответить
Ссылка на задачу — 3480. Maximize Subarrays After Removing One Conflicting Pair.
📌 Описание задачи
- Дан массив чисел от
1 до n и список конфликтных пар conflicting_pairs,
где каждая пара [a, b] запрещает подотрезки[1, n] , в которых a и b встречаются совместно.
- Требуется удалить ровно одну конфликтную пару так,
чтобы получить максимальное количество подотрезков из [1, n], удовлетворяющих оставшимся ограничениям.
Пример
- Входные параметры:
n = 5, conflictingPairs = [[1,2],[2,5],[3,5]]
- Ответ:
12
- Объяснение:
Удаляем [1, 2] из массива конфликтных пар. Остаются: [[2, 5], [3, 5]].
Всего 12 подотрезков удовлетворяют условию не содержать одновременно 2 и 5 или 3 и 5.
Это отрезки: 1..1, 1..2, 1..3, 1..4, 2..2, 2..3, 2..4, 3..3, 3..4, 4..4, 4..5, 5..5
💡 Идея
- Ключевое наблюдение заключается в том, что конфликтные пары создают ограничения на диапазоны, ограничивая допустимые подотрезки.
Читать дальше →
ответить
Очередная наша задача — 2579. Count Total Number of Colored Cells, как ни странно, красиво решается на шахматной доске ☺.
📜 Описание задачи
Дана бесконечная двумерная сетка с неокрашенными клетками. В течение n минут выполняются следующие действия:
- В первую минуту любая клетка окрашивается в синий цвет.
- В каждую следующую минуту закрашиваются все неокрашенные клетки, имеющие общую сторону с уже окрашенными.
Необходимо вычислить количество окрашенных клеток после n минут.
🧠 Идея
Если рассмотреть процесс закрашивания клеток на шахматной доске, можно увидеть, что в момент n окрашенные клетки образуют два наложенных квадрата:
- Квадрат размером
n × n
- Квадрат размером
(n-1) × (n-1)
Сумма площадей этих двух квадратов и дает общее количество окрашенных клеток.
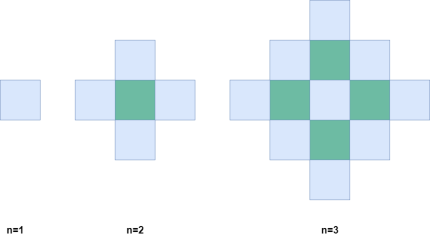
🚀 Детали подхода
✅ Применяем формулу: Total = n²+(n−1)²
⏳ Асимптотика
- Временная сложность:
O(1)
(мгновенный расчет по формуле)
- Пространственная сложность:
O(1)
(используется только переменная n)
💻 Исходный код
impl Solution {
pub fn colored_cells(n: i32) -> i64 {
let n = n as i64;
n*n + (n-1)*(n-1)
}
}
Tags: #rust #algorithms #math
ответить
Ссылка на задачу — 2140. Solving Questions With Brainpower.
📋 Описание задачи
- Дан вектор
questions (questions[i] = [pointsi, brainpoweri]).
- Вы проходите тест, состоящий из последовательности вопросов.
- Если вы решаете вопрос
i, то зарабатываете pointsi баллов, но пропускаете следующие brainpoweri вопросов.
- Вопросы можно пропускать
- Нужно определить, максимальное количество баллов, которое можно набрать, действуя оптимально.
📌 Пример:
- Вход:
questions = [[3, 2], [4, 3], [4, 4], [2, 5]]
- Размышления:
- Если решить вопрос
0, вы получите 3 очка и пропустите вопросы 1 и 2, перейдёте сразу к 3 → итого: 3 + 2 = 5.
- Если пропустить
0 и решить 1, вы получите 4 очка и пропустите 2 и 3 → итого: 4.
- Если пропустить
0 и 1, решить 2 → получите 4 очка, но пропустите 3 → итого: 4.
- Если пропустить
0–2 и решить 3 → получите 2 очка.
🔎 Оптимальная стратегия: решить вопросы 0 и 3, что даст нам 5 баллов на экзамене.
- 👉 Ответ:
5.
💡 Идея
Читать дальше →
ответить
Задача 6-го дня Advent of Code — Guard Gallivant.
📘 Часть I. Описание задачи
Нам требуется смоделировать движение охранника по лаборатории, представленной в виде сетки.
- Охранник начинает в определённой клетке, смотрит в одном из четырёх направлений и следует следующим правилам:
- Если перед ним препятствие (
#), он поворачивает направо на 90°.
- Иначе делает шаг вперёд.
Задача — определить количество уникальных клеток, которые охранник посетит, прежде чем покинет карту.
💡 Идея
Необходимо симулировать движение охранника, учитывая его текущую позицию и направление. Для отслеживания посещённых клеток используется двумерный массив, где каждая клетка хранит информацию о направлениях, с которых она была посещена. Если охранник возвращается в ту же клетку с тем же направлением, это означает начало цикла.
📘 Часть II. Описание задачи
Во второй части задачи требуется определить количество позиций, где добавление одного нового препятствия приведёт к тому, что охранник зациклится и никогда не покинет карту. Очевидно, что нельзя размещать препятствие в начальной позиции охранника.
💡 Идея
Читать дальше →
ответить
Ссылка на задачу — 2033. Minimum Operations to Make a Uni-Value Grid.
📌 Описание задачи
Дан двумерный массив grid размером m x n, а также число x.
За одну операцию можно прибавить или
Читать дальше →
ответить
Страница
1
2
3
4
