Следующая наша задача - 2559. Count Vowel Strings in Ranges.
📝 Описание задачи
Нам дан массив строк words и массив запросов queries, где каждый запрос задаётся парой [li, ri]. Необходимо для каждого запроса определить количество строк из диапазона [li, ri], которые начинаются и заканчиваются на гласные буквы ('a', 'e', 'i', 'o', 'u').
Вернуть массив ответов, где каждый элемент соответствует результату очередного запроса.
💡 Идея
Чтобы эффективно отвечать на диапазонные запросы, мы можем заранее подсчитать кумулятивные суммы валидных строк (начинающихся и заканчивающихся на гласные) в массиве префиксных сумм. Это позволяет сократить обработку каждого запроса до константного времени.
🔍 Подробности подхода
- Создание префиксных сумм:
- Сначала создаём итератор
prefix_sum_iter, вычисляющий кумулятивное количество "валидных" строк
(неплохой повод воспользоваться для этого методом std::iter::scan).
- Добавляем
0 в начало итогового массива (см. std::iter::once и std::iter::chain), чтобы упростить расчёты для запросов (исключая лишнюю проверку условий для обработки начала диапазона).
Читать дальше →
ответить
Ссылка на задачу – 1261. Find Elements in a Contaminated Binary Tree.
📝 Описание задачи
Дано двоичное дерево, в котором:
- Корень всегда имеет значение
0.
- Для каждого узла со значением
x:
- Если есть левый потомок, то его значение
2 * x + 1.
- Если есть правый потомок, то его значение
2 * x + 2.
Значения всех узлов загрязнены (-1).
Нужно реализовать структуру FindElements, которая:
- Принимает корень «загрязнённого» дерева в конструкторе.
- Реализует
find(target) — метод, проверяющий существует ли узел с таким значением.
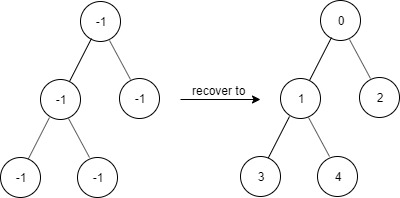
💡 Идея
Восстанавливать дерево не требуется!
Вместо этого мы вычисляем путь к узлу target, определяя его родителя и положение.
🔍 Детали подхода
- Поиск родителя (
parent):
Читать дальше →
ответить
Задача 4-го дня Advent of Code — Ceres Search.
📌 Часть I. Условие задачи
Нам дано поле из символов. Нужно найти все вхождения слова "XMAS".
Слово может быть записано:
- по горизонтали,
- по вертикали,
- по диагонали,
- в обратном порядке,
- поверх других слов (т.е. вхождения могут перекрываться).
💡 Идея
Для поиска всех таких слов:
- Перебираем каждую ячейку как потенциальную стартовую.
- Из неё идём во все
8 направлений (вверх, вниз, вправо, влево, и 4 диагонали).
- Читаем
4 символа в этом направлении.
- Сравниваем полученное слово с
"XMAS".
📌 Часть II. Условие задачи
Теперь требуется найти не само слово XMAS, а X-образное расположение двух слов "MAS" вокруг символа "A".
Пример расположения:
M . S
Читать дальше →
ответить
В очередной задаче для обзора - 802. Find Eventual Safe States нам предстоит найти вершины, не попадающие в циклы графа.
📋 Описание задачи
Нужно определить безопасные вершины в ориентированном графе.
- Безопасная вершина — это такая вершина, из которой невозможно попасть в цикл. Если из вершины можно попасть только в терминальные вершины или другие безопасные, она считается безопасной.
- Граф представлен в виде списка смежности, где
graph[i] содержит все вершины, в которые можно попасть из вершины i.
- Вернуть необходимо список всех безопасных вершин в возрастающем порядке.
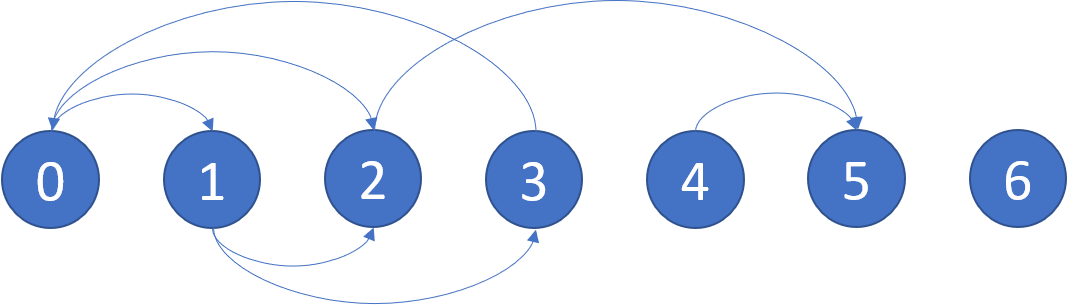
- Граф из примера имеет безопасными вершины:
[4,5,6]
💡 Идея
Задача решается с помощью обхода графа в глубину (DFS) и вектора состояний.
Каждому узлу присваивается одно из трёх состояний:
Unseen (ещё не обработан);Processing (в процессе обработки; узлы, являющиеся частью цикла, остаются в этом состоянии и после обработки);Safe (безопасный).
🔍 Детальное описание подхода
Читать дальше →
ответить
Ссылка на задачу – 1910. Remove All Occurrences of a Substring.
📌 Описание задачи
Даны две строки s и part. Нужно избавиться от всех вхождений part из s, выполняя следующую операцию:
- Найти самое левое вхождение
part в s и удалить его
- Повторять, пока
part больше не встречается в s.
🐢 Анализ наивного решения
Достаточно несложно быстро набросать следующее решение:
impl Solution {
pub fn remove_occurrences(mut s: String, part: String) -> String {
let P = part.len();
while let Some(idx) = s.find(&part) {
s.replace_range(idx..idx+P, "");
}
s
}
}
- Временная сложность такого решения в худшем случае достигает
O(N²/P)
Читать дальше →
1 ответ
Задача: 2940. Find Building Where Alice and Bob Can Meet
Описание задачи 📝
У нас есть массив heights, где heights[i] представляет высоту здания i.
Также даны запросы в виде массива queries, где каждый запрос [ai,bi>] требует определить самое левое здание, на которое могут попасть Алиса и Боб, начав с ai и bi соответственно, при соблюдении следующих условий:
- Алиса и Боб могут двигаться только в здания с индексами больше их текущего.
- Они могут перейти только на здания с высотой больше их текущей.
Если подходящее здание невозможно найти, результат для данного запроса равен −1.
Идея 💡
Мне сходу не известна эффективная структура данных для онлайн-разрешения запросов.
Но можно поступить хитрее, а именно:
- Немедленно обработать "простые" запросы, где результат очевиден.
- Для сложных запросов использовать технику отложенной обработки:
- Сначала отсортировать их по индексу правого здания.
- Затем разрешать запросы, итерируясь по зданиям, и, храня кандидатов на разрешение в двоичной куче.
Читать дальше →
ответить
Ссылка на задачу с LeetCode — 2179. Count Good Triplets in an Array.
📘 Условие задачи
Даны два массива nums1 и nums2, являющиеся перестановками чисел от 0 до n-1.
Нужно найти количество хороших троек (x, y, z), таких что:
- индексы этих значений возрастают в обоих массивах:
pos1(x)<pos1(y)<pos1(z) и pos2(x)<pos2(y)<pos2(z),- где
pos1(v) и pos2(v) — позиция значения v в nums1 и nums2 соответственно.
📌 Пример
- Вход:
nums1 = [2,0,1,3], nums2 = [0,1,2,3]
- Выход:
1
- Пояснение:
- Существуют 4 тройки, удовлетворяющие порядку в
nums1:
(2,0,1), (2,0,3), (2,1,3), (0,1,3)
- Из них только
(0,1,3) также удовлетворяет порядку в nums2.
💡 Идея
Рассматриваем каждое число как средний элемент потенциальной хорошей тройки.
Если знать, сколько подходящих чисел было до него и после него, можно посчитать количество троек с этим числом посередине.
Читать дальше →
ответить
Условие задачи — 2503. Maximum Number of Points From Grid Queries.
📘 Условие задачи
- Дана матрица
grid размером m × n и массив целых чисел queries, каждый из которых представляет пороговое значение.
- Для каждого запроса
queries[i] необходимо определить, сколько уникальных ячеек можно достичь, начиная с (0, 0), если разрешено:
- двигаться вверх, вниз, влево и вправо;
- заходить только в те ячейки, значение которых строго меньше
queries[i];
- Нужно вернуть массив
result, где result[i] — это общее количество очков, полученных для queries[i].
💡 Идея
Вместо того чтобы запускать поиск заново для каждого запроса, можно:
- выполнить один глобальный обход BFS, начиная с
(0, 0);
- посещать ячейки по возрастанию их значений (с помощью min-heap);
- на лету отвечать на все запросы, чьё значение не превышает текущей ячейки.
Такой метод за 1 проход отвечает сразу на все запросы.
🛠️ Детали реализации
- Сохраняем исходные индексы запросов и сортируем их по значениям.
Читать дальше →
ответить
Ссылка на задачу с LeetCode — 2338. Count the Number of Ideal Arrays.
📋 Описание задачи
Дан массив длины n, состоящий из целых чисел от 1 до maxValue. Массив называется «идеальным», если:
- Каждый элемент принадлежит диапазону
[1, maxValue]
- Каждый следующий элемент делится на предыдущий
Нужно посчитать количество различных идеальных массивов длины n.
Ответ вернуть по модулю 10⁹ + 7.
💬 Пример
- Вход:
n = 2, maxValue = 5
- Выход:
10
- Пояснение: Возможные идеальные массивы:
- Начинаются с
1 (5 массивов): [1,1], [1,2], [1,3], [1,4], [1,5]
- Начинаются с
2 (2 массива): [2,2], [2,4]
- Начинаются с
3 (1 массив): [3,3]
- Начинаются с
4 (1 массив): [4,4]
- Начинаются с
5 (1 массив): [5,5]
- Всего:
5 + 2 + 1 + 1 + 1 = 10 идеальных массивов.
💡 Идея
- Любую цепочку
i₀ → i₁ → ... → iₙ можно поделить на i₀, сведя задачу к подсчёту цепочек, начинающихся с единицы:
Читать дальше →
ответить
Задача - 1639. Number of Ways to Form a Target String Given a Dictionary
🔍 Описание задачи
Дано: список строк words одинаковой длины и строка target.
Цель: определить, сколькими способами можно собрать строку target, следуя правилам:
- В очередной шаг можно использовать символ, совпадающий с необходимым очередным символом
target, из любой допустимой позиции таблицы words.
- После выбора символа из определённой позиции все символы всех слов левее или равные этой позиции становятся недоступными.
- Вернуть количество способов по модулю
1_000_000_007
💡 Идея
Мы можем использовать подход динамического программирования. Для быстрого обновления состояний ДП предварительно подсчитаем частоты символов для каждой позиции в words.
Формула ДП:
Пусть dp[i][j] — количество способов собрать первые i символов строки target, используя первые j-й позиции в строках words. Тогда:
dp[i][j] = dp[i][j−1] + dp[i−1][j−1]⋅freqj(target[i]]), где:
Читать дальше →
ответить
В следующей задаче - 2661. First Completely Painted Row or Column можно не симулировать в лоб, и за счёт этого сэкономить память при решении (хоть и не получится асимптотически лучше).
📋 Описание задачи
- Нам дан массив
arr и матрица mat, содержащие числа от 1 до m * n.
- Массив
arr задаёт порядок закраски ячеек матрицы mat (закрашивается ячейка, содержащая указанное число).
- В следующем примере:
arr = [2,8,7,4,1,3,5,6,9], mat = [[3,2,5],[1,4,6],[8,7,9]]
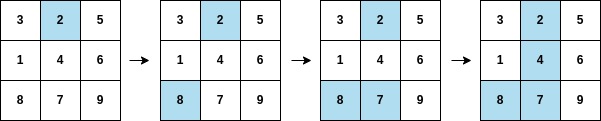
Необходимо найти первый такой индекс i в массиве arr, при котором:
- Либо вся строка, либо весь столбец матрицы окажется закрашенным.
💡 Идея
Задачу можно переформулировать:
- Каждая строка и каждый столбец закрашиваются, если все элементы строки/столбца обработаны в порядке массива
arr.
- Получается, что для решения задачи нужно:
- Найти максимальный индекс появления значений из
arr для каждой строки/столбца.
Читать дальше →
ответить
Задача на выходные - 2097. Valid Arrangement of Pairs
Описание задачи 📜
Нужно переставить заданные пары [starti,endi] так, чтобы получилось корректное расположение,
где для каждой пары i: endi−1=starti. Гарантируется, что такое расположение существует.
Обзор решения 🛠
Для решения задачи используется алгоритм Хирхольцера, который позволяет построить Эйлеров путь (или цикл) в ориентированном графе. Основная идея — удалять рёбра во время обхода, что упрощает структуру данных и предотвращает повторное использование рёбер.
Ключевые шаги 🚀
-
Построение графа:
- Граф представляется в виде списка смежности (
HashMap<i32, Vec<i32>>), где каждая вершина хранит список своих исходящих рёбер.
- Параллельно вычисляются разницы степеней вершин (входящих и исходящих рёбер) для определения начальной вершины пути.
-
Поиск начальной вершины:
- Начальная вершина — это вершина с положительным балансом исходящих рёбер. Если таких нет, берётся любая вершина из входных данных.
-
Итеративный DFS с удалением рёбер:
- Вместо стандартного рекурсивного DFS используется итеративный подход с явным стеком. Это повышает эффективность памяти и скорость.
- При посещении вершины рёбра удаляются из списка смежности, что гарантирует, что каждое ребро используется ровно один раз.
Читать дальше →
ответить
Задача пятого дня Advent of Code - Print Queue.
📘 Часть I. Условие задачи
- Набор страниц необходимо печатать в определённом порядке.
- Каждое правило задаётся в виде
X | Y, что означает: если обе страницы X и Y присутствуют в обновлении, то X должна появиться раньше Y.
- Дан список правил и набор последовательностей страниц.
- Требуется найти те, которые уже соответствуют правилам, и для каждой взять среднюю (центральную) страницу.
- Сумма этих страниц и является ответом.
💡 Идея
Для проверки корректности можно обходить последовательность и накапливать множество страниц, которые должны были уже встретиться раньше.
Если мы наткнемся на одну из них позже зависимой страницы, это нарушение!
📘 Часть II. Условие задачи
Теперь рассмотрим некорректные последовательности страниц.
Их нужно перестроить согласно правилам и взять сумму центральных страниц из корректных порядков.
💡 Идея
Это задача на топологическую сортировку.
- Правила определяют DAG (граф без циклов).
Читать дальше →
ответить
Задача: 2872. Maximum Number of K-Divisible Components
Описание задачи 📋
Дано неориентированное дерево с n узлами, пронумерованными от 0 до n−1. Также даны:
- массив рёбер edges, где каждое ребро связывает два узла,
- массив значений values, где значение values[i] связано с узлом i,
- число k.
- гарантируется, что сумма всех значений values кратна k
Необходимо найти максимальное количество компонентов, на которые можно разделить дерево, удаляя рёбра, чтобы сумма значений в каждом компоненте делилась на k.
Идея 💡
Будем разбивать дерево на компоненты рекурсивно (DFS), начиная с произвольного узла.
Несложно показать, что родительская вершина должна быть в одной компененте со всеми дочерними, для которых сумма значений в соответствующем поддереве не делится на k.
Детали подхода 🚀
-
Построение графа:
- Представляем дерево в виде списка смежности для удобного обхода.
-
Обход дерева:
Читать дальше →
ответить
Ссылка на задачу — 2460. Apply Operations to an Array.
📝 Описание задачи
Дан массив nums, состоящий из неотрицательных целых чисел. Нужно последовательно выполнить следующие операции:
- Для каждого валидного
i (в порядке возрастания):
- eсли
nums[i] == nums[i + 1], удвоить nums[i] и заменить nums[i + 1] на 0.
- После всех операций сдвинуть все нули в конец массива, сохраняя порядок оставшихся чисел.
- Вернуть изменённый массив.
💡 Идея
Решение можно выполнить за один проход, используя два указателя (read и write):
- Читаем массив и объединяем соседние одинаковые элементы.
- Перемещаем ненулевые элементы в начало массива.
- Оставшиеся ячейки заполняем нулями.
Такой подход позволяет изменять массив на месте, не используя дополнительную память.
📌 Детали подхода
- Используем два указателя (
read и write):
read проходит по массиву.write отслеживает следующую позицию для ненулевых чисел.
Читать дальше →
ответить
Сегодня мы разберём задачу 916. Word Subsets.
📝 Описание задачи
Вам даны два массива строк words1 и words2.
Задача: найти все строки из words1, которые являются универсальными относительно всех строк из words2.
Условие универсальности:
Строка a из words1 универсальна, если для каждой строки b из words2 строка b является подмножеством строки a (Подмножество строки: строка b является подмножеством строки a, если каждая буква в b встречается в a как минимум столько же раз).
Пример:
["warrior", "world"] и ["wrr"]
Ответ: ["warrior"], так как только warrior покрывает все буквы из wrr.
💡 Идея
Для эффективного решения задачи:
- Определим максимальное количество вхождений каждой буквы по всем строкам из words2.
- Для каждой строки из words1 проверим, удовлетворяет ли она этим требованиям.
🔍 Детали подхода
Читать дальше →
ответить
Наша очередная задача - 1930. Unique Length-3 Palindromic Subsequences.
📝 Описание задачи
Дана строка s. Необходимо определить количество уникальных палиндромов длины 3, которые являются подпоследовательностями строки.
Подпоследовательность — это строка, полученная из исходной строки удалением некоторых (возможно, нуля) символов без изменения их порядка. Например, для строки "abcde" строка "ace" является подпоследовательностью.
Палиндром — это строка, которая читается одинаково в прямом и обратном направлениях.
💡 Идея
Основная идея заключается в том, что палиндром длины 3 определяется первыми и последними символами, которые совпадают, а также любым допустимым символом посередине.
Мы можем эффективно отслеживать такие пары (первый и последний символы) с помощью битового массива (bitset), что позволяет минимизировать использование памяти.
🔍 Детали подхода
- Массивы частот:
prefix_frequency: хранит частоты символов слева от рассматриваемого.suffix_frequency: хранит частоты символов справа от рассматриваемого.
Читать дальше →
ответить
Задача, что мы рассмотрим сегодня - 2948. Make Lexicographically Smallest Array by Swapping Elements
📝 Описание задачи:
- Дан массив положительных чисел
nums и положительное число limit.
- Разрешено менять местами элементы массива
nums[i] и nums[j], если выполняется условие:
|nums[i] - nums[j]| <= limit.
- Необходимо получить лексикографически минимальный массив, выполняя такие операции любое количество раз.
Лексикографический порядок: Массив a меньше массива b, если на первой позиции i, где они различаются, a[i] < b[i].
💡 Идея:
Будем эксплуатировать следующие замечания:
- Элементы могут менять местами только внутри определённых групп, где (после её вырезания и сортировки) выполняется условие:
|nums[group[i+1]] - nums[group[i]]| <= limit.
- Индексная сортировка по значениям
nums поможет нас найти группы, внутри которых возможны перестановки.
- Сортировка каждой из этих групп может быть эффективно выполнена с помощью дополнительного индексного массива.
🔍 Детали подхода:
- Сортировка индексов: На первом шаге создаём массив
sorted_indices, заполняя его значениями [0, 1, ..., n-1]. Затем сортируем этот массив по значениям массива nums, чтобы определить относительный порядок элементов.
Читать дальше →
ответить
Задача 9 дня Advent of Code — Disk Fragmenter.
😊 Часть I. Описание задачи
На диске из N секторов хранятся файлы, каждый занимая непрерывный блок секторов. Между блоками могут быть «пробелы» (свободные сектора).
- Задача: последовательно перемещать по одному сектору каждого файла (начиная с конца списка) в самый левый доступный свободный сектор, пока не исчезнут все разрывы.
- Пример:
В начале: 00...111...2...333.44.5555.6666.777.888899После: 0099811188827773336446555566..............
😊 Часть II. Описание задачи
Теперь вместо по-секторного перемещения перемещаем файлы целиком, один раз для каждого файла, в порядке убывания file_id. Для каждого файла (перебираем справа-налево) ищем самый левый свободный диапазон длины ≥ размера файла;
если он находится левее текущего — перемещаем файл, иначе оставляем на месте.
- Пример:
В начале: 00...111...2...333.44.5555.6666.777.888899После: 00992111777.44.333....5555.6666.....8888..
💡 Идея решения
Строим дерево отрезков над массивом из N секторов.
Читать дальше →
ответить
Сегодня нам предстоит решить задачу 1792. Maximum Average Pass Ratio.
Описание задачи 📚
У нас есть школа, где классы проводят итоговые экзамены. Каждый класс описывается массивом [pass_i,total_i], где:
pass_i — количество учеников,
Читать дальше →
2 ответа
На этот раз наша задача выглядит заковыристо - 2982. Find Longest Special Substring That Occurs Thrice II.
📝 Описание задачи
Необходимо найти длину самой длинной "особенной" подстроки, которая встречается в строке хотя бы три раза. Если такой подстроки нет, вернуть -1.
"Особенная" подстрока — это подстрока, содержащая один и тот же символ.
😊 Идея
Отбросим сразу идею перебора всех возможных подстрок (что крайне неэффективно).
Вместо этого мы сосредоточимся на последовательных участках каждого символа.
Для каждого символа достаточно рассмотреть только длины его подряд идущих сегментов, и это позволит нам эффективно вычислить искомый результат.
🚀 Подход
- Перебираем все строчные английские буквы (
'a' до 'z').
- Для каждой буквы:
- Находим все её подряд идущие сегменты (например, для
'aaaabbaab' сегменты: [4,2], [2,1] для 'a' и 'b').
- Сортируем длины сегментов по убыванию.
- Вычисляем максимальную возможную длину "особенной" подстроки, встречающейся как минимум три раза, используя метод
get_triple_length.
Читать дальше →
4 ответа
Ссылка на задачу – 3105. Longest Strictly Increasing or Strictly Decreasing Subarray.
😎 Описание задачи
Дан массив целых чисел nums. Необходимо найти длину самой длинной последовательности, которая является либо строго возрастающей, либо строго убывающей.
🤔 Идея
Разбить массив на группы (чанки) по непрерывной монотонности (либо возрастающей, либо убывающей).
Для каждой группы вычислить её длину, а затем выбрать максимальное значение среди всех групп.
🚀 Детали подхода
- Разбиение на чанки:
Используем метод chunk_by для разбиения массива:
- Для строго возрастающей последовательности используем сравнение
a < b.
- Для строго убывающей последовательности используем сравнение
a > b.
- Вычисление максимальной длины:
- Для каждого набора чанков вычисляем длину каждой группы, выбираем максимальную длину для возрастающих и убывающих групп.
- Результат:
- Возвращаем максимум между максимальной длиной возрастающей и максимальной длиной убывающей последовательности.
⏱ Асимптотика
- Время:
O(n) — каждый элемент обрабатывается один раз при разбиении на чанки.
- Память:
O(1) — используется дополнительная память только для итераторов, не зависящая от размера входного массива.
📜 Исходный код
impl Solution {
pub fn longest_monotonic_subarray(nums: Vec<i32>) -> i32 {
// Group strictly increasing segments using chunk_by
let max_increasing_len = nums.chunk_by(|a, b| a < b)
.map(|c| c.len()).max().unwrap_or(0);
// Group strictly decreasing segments using chunk_by
let max_decreasing_len = nums.chunk_by(|a, b| a > b)
.map(|c| c.len()).max().unwrap_or(0);
max_increasing_len.max(max_decreasing_len) as i32
}
}
Tags: #rust #algorithms #iterators
1 ответ
Условие задачи — 2874. Maximum Value of an Ordered Triplet II.
📄 Описание задачи
Дан массив целых чисел nums (индексация с нуля).
Нужно найти максимум выражения (nums[i]-nums[j])·nums[k] среди всех троек индексов i < j < k.
Если все такие значения отрицательны, вернуть 0.
💡 Идея
Выражение (nums[i]-nums[j])·nums[k] будет наибольшим, при фиксированном k, если:
- Число
nums[i] наибольшее
- Разность
nums[i]-nums[j] максимальна
Значит, на каждом шаге мы можем поддерживать максимальное значение разности (nums[i]-nums[j]) до текущего индекса и умножать его на nums[k], обновляя лучший результат.
🔍 Детали подхода
- Идем по массиву слева направо. На каждом шаге:
max_val хранит максимум из всех предыдущих чисел (nums[..i]);max_diff — максимум nums[i]-nums[j] на текущий момент;- умножаем
max_diff на текущий nums[k] и обновляем best.
- Всё делается за один проход, без дополнительных структур данных.
⏱️ Асимптотика
- Время:
O(n) — один проход по массиву
- Память:
O(1) — используются только 3 переменные
🧾 Исходный код
impl Solution {
pub fn maximum_triplet_value(nums: Vec<i32>) -> i64 {
nums.into_iter().fold((0i64, 0, 0), |(best, max_diff, max_val), x| (
best.max(x as i64 * max_diff as i64),
max_diff.max(max_val - x),
max_val.max(x),
)).0
}
}
Tags: #rust #algorithms #greedy
ответить
Ссылка на задачу — 763. Partition Labels.
📄 Описание задачи
- Дана строка
s, состоящая только из строчных латинских букв.
- Нужно разбить строку на как можно большее количество подстрок, таких что каждая буква встречается не более чем в одной подстроке.
- После разбиения объединение всех подстрок в порядке следования должно дать исходную строку.
- Например, для строки
"ababcc" корректное разбиение: ["abab", "cc"].
А такие варианты, как ["aba", "bcc"] или ["ab", "ab", "cc"] — недопустимы, потому что буквы повторяются в нескольких частях.
- Нужно вернуть список размеров всех полученных подстрок.
💡 Идея
Каждая буква должна присутствовать в одной части.
Значит, можно рассматривать все буквы как интервалы [первая позиция, последняя позиция].
Теперь задача сводится к жадному объединению перекрывающихся интервалов: как только текущий интервал завершился, мы фиксируем подстроку.
🔍 Детали подхода
- Проходим по строке один раз, чтобы:
- определить первую и последнюю позицию каждой буквы;
- зафиксировать порядок появления символов.
- Затем проходим по символам алфавита в порядке первого появления:
Читать дальше →
ответить
Ссылка на задачу - 2161. Partition Array According to Given Pivot.
В данной задаче нам предстоит реализовать базовую подзадачу Быстрой сортировки, но с дополнительным требованием сохранения относительного порядка, отчего стандартные методы реализации Q-sort нас не будут устраивать ☹
📌 Описание задачи
Дан массив nums и число pivot. Требуется переставить элементы массива так, чтобы:
- Все элементы меньше
pivot шли первыми.
- Все элементы равные
pivot находились в середине.
- Все элементы больше
pivot шли в конце.
- Относительный порядок элементов в каждой группе сохранялся.
💡 Идея
Мы хотим разделить массив на три части, не создавая лишние структуры данных.
Вместо этого заполним результирующий вектор напрямую, обрабатывая массив в три прохода.
🛠️ Детали подхода
1️⃣ Первый проход: добавляем в результат все элементы < pivot.
2️⃣ Подсчет и второй проход: вычисляем количество вхождений pivot в массиве и добавляем pivot в результат pivot_count раз.
3️⃣ Третий проход: добавляем все элементы > pivot в результат.
Используем Vec::with_capacity(nums.len()), чтобы избежать лишних аллокаций.
📊 Асимптотика
- Временная сложность:
O(n) — три прохода по nums.
- Дополнительная память:
O(1) — все данные хранятся только в результирующем массиве
(который всё же имеет размер O(n)).
💻 Исходный код
impl Solution {
pub fn pivot_array(nums: Vec<i32>, pivot: i32) -> Vec<i32> {
let mut result = Vec::with_capacity(nums.len());
// First pass: Collect elements smaller than pivot
result.extend(nums.iter().filter(|&&num| num < pivot));
// Count occurrences of pivot
let pivot_count = nums.iter().filter(|&&num| num == pivot).count();
// Insert pivot elements
result.extend(std::iter::repeat(pivot).take(pivot_count));
// Third pass: Collect elements greater than pivot using into_iter() to take ownership
result.extend(nums.into_iter().filter(|&num| num > pivot));
result
}
}
Tags: #rust #algorithms
1 ответ
Страница
1
2
3
4
